Self-Improving Reasoning LLMs through Priming: Why it Works for Some Models but Not Others
Applying Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs to LLM Development
I have a print on my office wall with the Philip K Dick quote, “I wonder what the machines will think.” I bought it from a stand at the Brooklyn Book Fair in 2018. Seven years later, some three years into the new AI boom, I spend less time wondering what machines think than I do how they think it.

One prototype I built in 2024 implemented the Self-Discover Whitepaper (Zhou et al 2024). This approach to LLM reasoning has a few core steps:
- Provide a set of reasoning modules, showing different ways of structuring a reasoning problem, such as:
- Use systems thinking: Consider the problem as part of a larger system and understanding the interconnectedness of various elements. Focuses on identifying the underlying causes, feedback loops, and interdependencies that influence the problem, and developing holistic solutions that address the system as a whole.
- Use Risk Analysis: Evaluate potential risks, uncertainties, and tradeoffs associated with different solutions or approaches to a problem. Emphasize assessing the potential consequences and likelihood of success or failure, and making informed decisions based on a balanced analysis of risks and benefits.
- Filter down to relevant reasoning modules at query-time
- Use the reasoning pattern(s) in the LLM call to “prime the pump” and encourage the LLM to apply that reasoning module to the problem at hand
This kind of process is not unique. I’ve used similar approaches in AI development with TextGrad, DSPy, and in projects without any frameworks. Examples, be they inputs from a user or “reasoning modules” from a framework, are so powerful as a pattern that they’re tablestakes for most application-level LLM calls in production.
Providing a LLM with a set of reasoning patterns is one thing, getting that model to reliably apply them to new inputs is another endeavor entirely. Consider smaller models like llama3.2 and command-r7b. Can we use reasoning patterns to meaningfully improve the quality of our outputs?
Yes and no. In my own testing, I could get llama3.2 to follow a couple reasoning patterns (e.g. sequential task decomposition) one some inputs, but it was hit-or-miss. In contrast, qwen2.5 caught on to reasoning patterns much more reliably.
Why can some models properly apply reasoning patterns while others cannot? At the time, I chalked qwen2.5’s results to it being a newer and more capable model with better training for reasoning chains. This isn’t wrong necessarily, but its also imprecise. There is a real explanation.
Why can some models properly apply reasoning patterns while others cannot?
I recently came across a new paper from Stanford University researchers that tackles exactly this question: Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs (Gandhi et al 2025).
The paper begins with a similar observation - that some models can be “primed” for self-improvement through reasoning, while others improve some but quickly plateau with the same priming. The researchers identify four cognitive traits that a model must possess to improve their reasoning:
- Verification - The model is able to apply error checking to its reasoning/output. E.g., “This approach won’t work because”
- Backtracking - The model can abandon dead-ends or failing approaches to a problem. E.g., “Lets verify this result by…”
- Subgoal setting - The model can perform task decomposition on an input to split it into appropriately sized steps. E.g., “To solve this, we first need to…”
- Backwards chaining - The model can reason about an input instruction based on the desired result. E.g., “To reach the target of 75, we need a number divisible by…”
The STaR models in the title refers to Self-Taught Reasoner Models whitepaper, which showed that a model can improve its reasoning by consuming reasoning chains. The original STaR paper applies reasoning chains for model improvement through a simple loop:
generate rationales to answer many questions, prompted with a few rationale examples; if the generated answers are wrong, try again to generate a rationale given the correct answer; fine-tune on all the rationales that ultimately yielded correct answers; repeat
This process makes some sense - we only apply reasoning chains that were correct , since reasoning chains that lead to a false result are more likely to have flaws in the reasoning steps themselves.
However, the most surprising outcome from Cognitive Behaviors is that the correctness of a reasoning chain’s result does not change the utility of that reasoning chain when applied to a RL model. Or, put another way, the usefulness of reasoning chains lies in how they think through a problem, not in what they think within a reasoning step or its final outcome.
these gains persist even when primed on incorrect solutions, if they exhibit proper reasoning patterns, suggesting that the presence of reasoning behaviors, rather than access to correct solutions, is the critical factor enabling successful self-improvement
In humans, reasoning structures like these are the atomic elements of understanding. Our ability to combine, apply, and adjust structured thought in across domains allows us to adapt to novel problems. Papers like Cognitive Behaviors feel like a mashup of Noam Chomsky-style nueroscience and modern computing research because they are: AI research is now at a point where its uncontroversial to use the language of nueroscience and cognition to talk about language models.
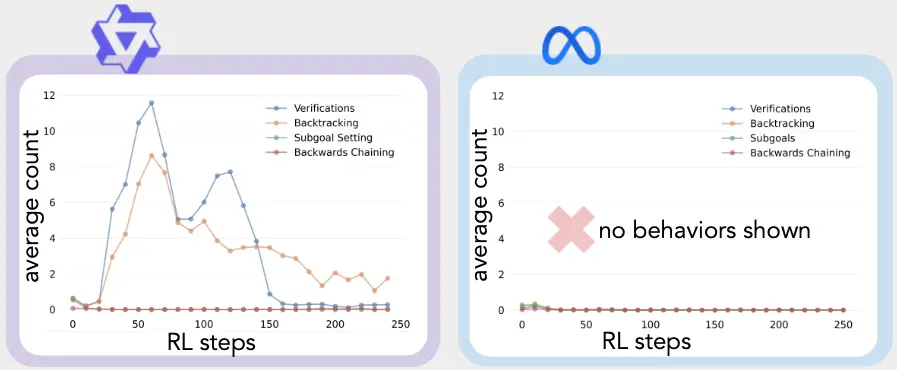
When I compared qwen2.5 and llama3.2, now more than a year ago, the reason why qwen could naturally reason and llama3.2 could not seemed mysterious - something to do with their training datasets, perhaps. But this Stanford research provides a mechanistic explanation for these differences: the presence of these four fundamental cognitive behaviors in qwen2.5 that were either absent or underdeveloped in llama3.2.
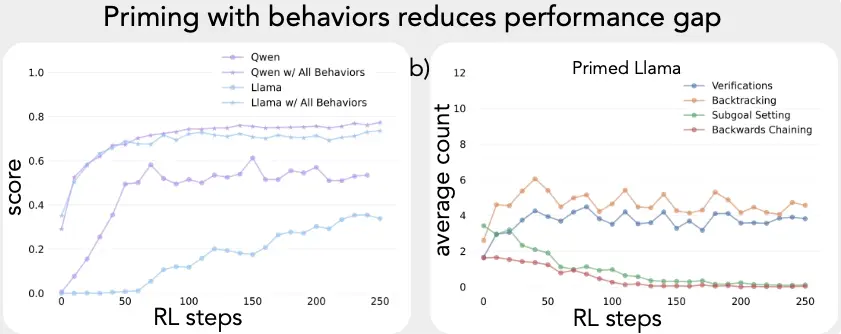
Now that we can measure which models naturally have these four behaviors, we can dramatically narrow the range of suitable small language models for a given task. Then, we enhance the model further by priming it with reasoning chains. But priming across all categories of reasoning isn’t without drawbacks: “Behavioral analysis reveals that RL selectively amplifies empirically useful behaviors while suppressing others.” So, priming one kind of reasoning capability can diminish another. When the researchers primed all four behaviors, “the models retain and strengthen backtracking and verification while diminishing backward chaining and subgoal setting.” Yet priming three of the four, excluding the Verification behavior, resulted in the suppressed behaviors persisting.
So there will need to be some careful priming when applying this technique to a use case (The measurements in Cognitive Behaviors were structured around the “Countdown” game, so very much not generalized across domains). And within that use case, a careful balance of primed reasoning behaviors.
The Cognitive Behaviors paper is in the back of my mind every time I select a small model for a task, and every time I run optimizations on any model. For reasoning systems, these 4 behaviors act as categories I use to organize example reasoning chains. There’s still no shortcut to properly A/B testing models against one another, but now we have a base understanding of why certain models struggle to follow different reasoning patterns.
I used to think of my interests in the Humanities and Computer Science as two distinct disciplines. This year especially, more and more of CS research is taking on a Chomskian bend. The implications of computer science research on phenomenology, sociology, literary theory and other fields feel less like empty gestures in abstracts and conclusions, and more like integral components required for understanding the research itself.
I don’t wonder what the machines think - they’re more than happy to show their long and often deranged internal monologue between <think> tags. But in wondering how they think, the sort of answer we’re closing in on feels less like the speculative fiction of Philip K. Dick and more like Chomsky’s writing- in which many disciplines are blended and pulped into something new.